Hybrid CNN-LSTM network to detect Dysarthria using Mel-Frequency Cepstral Coefficients
Abstract
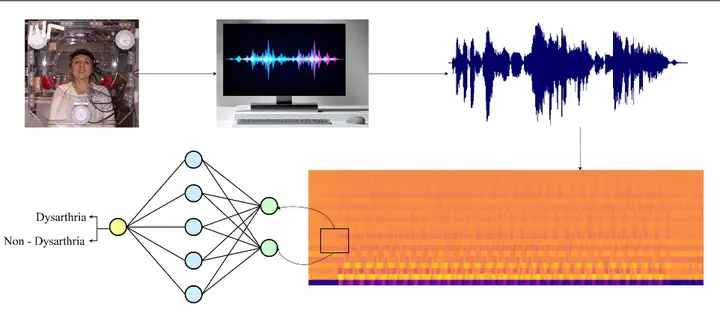
Dysarthria is a speech problem acquired at birth due to cerebral palsy (CP) or developed after severe brain damage. Dysarthria affects more than 70% of Parkinson’s patients and 10% to 65% of people with traumatic brain injury. It is critical to detect dysarthria and other voice speech difficulties early to diagnose the underlying cause. Intelligent systems capable of identifying dysarthria with incredible precision have been developed using audio processing techniques and various deep learning models. This paper presents a hybrid CNN-LSTM model for classifying patients with dysarthria using audio recordings. The CNN-LSTM combination helps capture spatial and temporal information where CNN acts as a feature extractor while LSTM functions as a classifier. The proposed model was trained on the publicly available 9184 audio recordings from the TORGO dataset, and various audio augmentation techniques were employed to generate synthetic data. A total of 128 features were extracted using Mel Frequency Cepstral Coefficients (MFCC) and fed into the architecture as inputs. The K-fold cross-validation technique was used to avoid overfitting and increase the generalization capability of the model. The proposed architecture achieved a state-of-the-art 99.59% accuracy on the dataset. The presented work will minimize the workload of speech pathologists and help them detect dysarthria precisely and effectively.
Dishant Padalia
Computer Science Master’s Student at UMass Amherst
My research interests include computer vision, AI in healthcare and natural language processing.